 v-for中的key作用
v-for中的key作用
# 快速、简洁讲明Vue中v-for循环key的作用
# 概要
关于v-for中的key问题,其实这已经是个很常见的问题了,基本网上一搜一大把,面试的时候也常常会被问到,讲这个问题可能会设计DOM与虚拟DOM,还有很重要的Diff算法。传送门
# 作用(重头戏)
我们都知道,Vue很大的一个特点就是双向数据绑定,数据一旦改变,那么页面就渲染新的数据呈现在页面上。
那么问题来了,对于用v-for渲染的列表数据来说,数据量可能一般很庞大,而且我们经常还要对这个数据进行一些增删改操作。
假设我们给列表增加一条数据,整个列表都要重新渲染一遍,那不就很费事了。
而key的出现就是尽可能的回避这个问题,提高效率,如果我们给列表增加了一条数据,页面只渲染了这数据,那不就很完美了。
v-for默认使用就地复用策略,列表数据修改的时候,他会根据key值去判断某个值是否修改,如果修改,则重新渲染这一项,否则复用之前的元素。
我们经常使用会使用index(即数组的下标)作为key,但其实不推荐怎么使用。
# 例如:
list = [
{
id: 1,
num: 1
},
{
id: 2,
num: 2
},
{
id: 3,
num: 3
},
];
2
3
4
5
6
7
8
9
10
11
12
13
14
<div v-for="(item, index) in list" :key="index">
{{item.num}}
</div>
2
3
上面这种情况我们使用了index作为了key。
1.在数组后面追加一条数据
list = [
{
id: 1,
num: '1'
},
{
id: 2,
num: 2
},
{
id: 3,
num: 3
},
{
id: 4,
num: '新增加的数据4'
}
];
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
此时前三条数据页面不会重新渲染,直接复用之前的,只会新渲染最后一条数据,此时用index作为key,没有任何问题。
2.在数组中间插入一条数据
list = [
{
id: 3,
num: 1
},
{
id: 4,
num: '新增加的数据4'
},
{
id: 2,
num: '2'
},
{
id: 3,
num: '3'
}
];
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
页面在去渲染数据的时候,通过index定义的key的比较,会有:
之前的数据 之后的数据
key: 0 index: 0 num: 1 key: 0 index: 0 num: 1
key: 1 index: 1 num: 2 key: 1 index: 1 num: '新增加的数据4'
key: 2 index: 2 num: 3 key: 2 index: 2 num: 2
key: 3 index: 3 num: 3
2
3
4
5
6
通过上面清晰的对比,发现除了第一个数据可以复用之前的之外,另外三条数据都需要重新渲染。
是不是很惊奇,我明明只是插入了一条数据,怎么三条数据都要重新渲染?而我想要的只是新增的那一条数据新渲染出来就行了。
最好的办法是使用数组中不会变化的那一项作为key值,对应到项目中,即每条数据都有一个唯一的id,来标识这条数据的唯一性。
使用id作为key值,我们再来对比一下向中间插入一条数据,此时会怎么去渲染呢?例如:
list = [
{
id: 1,
num: 1
},
{
id: 4,
num: '新增加的数据4'
},
{
id: 2,
num: 2
},
{
id: 3,
num: 3
}
];
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
之前的数据 之后的数据
key: 1 id: 1 index: 0 num: 1 key: 1 id: 1 index: 0 num: 1
key: 2 id: 2 index: 1 num: 2 key: 4 id: 4 index: 1 num: '新增加的数据4'
key: 3 id: 3 index: 2 num: 3 key: 2 id: 2 index: 2 num: 2
key: 3 id: 3 index: 3 num: 3
2
3
4
5
6
现在对比发现只有一条数据变化了,就是id为4的那条数据,因此只要新渲染这一条数据就可以了,其他都是就复用之前的。
同理在react中使用map渲染列表时,也是必须加key,且推荐做法也是使用id,也是这个原因。
其实,真正的原因并不是vue和react怎么怎么,而是因为Virtual DOM 使用Diff算法实现的原因。
# 关于Diff简析
当页面的数据发生变化时,Diff算法只会比较同一层级的节点。
如果节点类型不同,直接干掉前面的节点,再创建并插入新的节点,不会再比较这个节点的子节点了。
如果节点类型相同,则会重新设置该节点的属性,从而实现节点的更新。
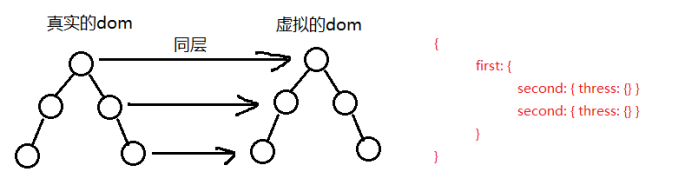
# 举个例子
我们往一个列表里面插入一条数据:

Diff算法默认执行的是这样子:
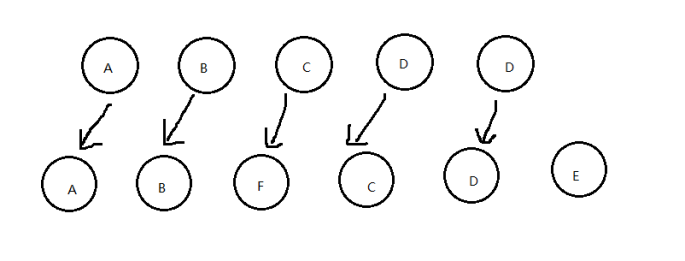
这样子的话效率就很慢了,这时需要使用key来给每个节点做一个唯一标识,Diff算法就可以正确的识别此节点,找到正确的位置区插入新的节点。